With ISC Prime Efficiency 2022 going down this week in Hamburg, Germany, Intel is the usage of the primary in-person model of the development in 3 years to provide an replace to the state in their excessive functionality/supercomputer silicon plans. The large information out of the display this 12 months is that Intel is naming the successor to the Ponte Vecchio accelerator, which the corporate is now disclosing as Rialto Bridge.
Prior to now showing on Intel’s roadmaps as “Ponte Vecchio Subsequent”, Intel’s GPU groups had been pipelining the advance of Ponte’s successor at the same time as the primary huge set up of Ponte itself (the Aurora Supercomputer) continues to be being stood up. As a part of the corporate’s 3 12 months (ish) roadmap that ends up in CPUs and accelerators converging with the Falcon Shores XPU, Rialto Bridge is the section that may, should you’ll pardon the pun, bridge the space between Ponte and Falcon, providing an evolution of Ponte’s design that’s applying more moderen applied sciences and production processes.

Whilst Intel isn’t providing an absolutely detailed technical breakdown this early within the procedure, at a excessive point the corporate is speaking a little bit about specs, in addition to offering a render of the longer term chip that eliminates all doubt that it’s a Ponte successor, showcasing that it’s made from dozens of tiles/chiplets in the similar format as Ponte. The most important alternate that Intel is speaking about nowadays is they’ll be increasing the overall collection of Xe compute cores from 128 on Ponte to a most of 160 on Rialto Bridge – probably by way of expanding the collection of Xe cores in every compute tile.

Absent any concrete main points at the production aspect of issues, Intel is no less than confirming that Rialto will use more moderen production nodes for its development, changing its present mixture of TSMC N7 (Hyperlink Tile), TSMC N5 (Compute), and Intel 7 (Cache & Base) portions. The Intel 4 procedure is anticipated to return on-line this 12 months, so the usage of that to improve the Base and Cache would make sense. Preferably, Intel would additionally like to leap ahead on procedure nodes for the compute tiles as neatly, perhaps by way of the usage of this chance to transport manufacturing of the ones tiles to Intel 4 – regardless that we wouldn’t depend out TSMC N4, both.
With that stated, on the chance of studying an excessive amount of right into a unmarried renderer, Rialto has one noticeable distinction from Ponte in terms of the compute cores: while Ponte used pairs of compute cores with a cache tile in between, Rialto in the beginning look would appear to be the usage of monolithic slabs. This signifies that Intel has opted to combine the Rambo cache on-die with the compute tiles, and that they’re keen to fab fewer, better compute tiles. This does lend some credence to the concept Intel is taking up compute tile production (since they already make the cache tiles), however we’ll have to look simply what Intel broadcasts in a while.
Curiously, Intel may be promising extra I/O bandwidth for Rialto – regardless that once more, it is a very high-level (and unspecific) element. Ponte is already one of the most first merchandise delivery with PCIe 5.0 connectivity, and with PCIe 6.0 {hardware} nonetheless a little bit off, this can be extra about on-chip bandwidth than off-chip bandwidth, or in regards to the quantity of bandwidth to be had between accelerators the usage of Intel’s Xe Hyperlink interconnect.
HBM3 may be a shoe-in for Intel’s next-generation accelerator, for the reason that it’s already going into accelerators delivery this 12 months. HPC accelerators with regards to reside and die in response to reminiscence bandwidth, so we think that it will be the very first thing Intel checked out for Rialto. And it will be in line with Intel’s awkwardly phrased “Extra GT/s” since reminiscence bandwidth is incessantly measured in gigatransfers.
In any case, Intel is declaring that Rialto shall be founded round a more moderen model of the Open Accelerator Module (OAM) socket specification, which is especially notable because the subsequent model of OAM has but to be introduced. Absent extra main points, the largest differentiating issue appears to be supported energy – while OAM 1.x permits for modules to attract as much as 700 Watts, Intel is speaking about doing as much as 800 Watts on a Rialto module. Which, for higher or worse, is in line with the rise in energy intake for the best possible appearing variations of the following technology of HPC accelerators, and is a large issue within the shift to liquid and immersion cooling for high-end {hardware}.
| Compute GPU Accelerator Comparability | |||
| AnandTech | Intel | Intel | NVIDIA |
| Product | Rialto Bridge | Ponte Vecchio | H100 80GB |
| Structure | Xe-HPC | Xe-HPC | Ampere |
| Transistors | ? | 100 B | 80 B |
| Tiles (inc HBM) | 31? | 47 | 6 + 1 spare |
| Compute Gadgets | 160 | 128 | 132 |
| Matrix Cores | 1280? | 1024 | 528 |
| L2 / L3 | ? | 2 x 204MB | 50MB |
| VRAM Capability | ? | 128 GB | 80 GB |
| VRAM Kind | HBM3? | 8 x HBM2e | 5 x HBM3 |
| VRAM Width | ? | 8192-bit | 5120-bit |
| VRAM Bandwidth | ? | ? | 3.0 TB/s |
| Chip-to-Chip Overall BW | ? | 64 x 11.25 GB/s (4×16 90G SERDES) |
18 x 50 GB/s |
| CPU Coherency | Sure | Sure | With NVLink 4 |
| Production | ? | Intel 7 TSMC N7 TSMC N5 |
TSMC N4 |
| Shape Elements | OAM 2.0 (800W) | OAM (600W) | SXM4 (400W*) |
| Free up Date | Mid-2023 (Sampling) | 2022 | 2022 |
| *Some Customized deployments pass as much as 600W | |||
Total, Intel is concentrated on a 30% build up in “software point” functionality with Rialto bridge. Which in the beginning blush isn’t an enormous acquire, nevertheless it’s additionally for an element that’s popping out round a 12 months after the unique Ponte Vecchio. The 25% build up within the collection of Xe cores implies that maximum of this functionality uplift will have to be delivered by way of the extra {hardware} versus clockspeed adjustments, however since Intel is quoting real-world functionality expectancies versus simply theoretical throughput, we wouldn’t be too stunned if Rialto’s on-paper specifications had been a little bit richer nonetheless. Intel may be promising that Rialto will have to be extra environment friendly than Ponte, which at face worth is an affordable declare since functionality will have to be going up quicker than energy intake.
In line with Intel’s roadmap, the plan is to have Rialto Bridge get started sampling in mid-2023. Given Intel’s troubles getting Ponte Vecchio out on time – you continue to can’t get it until you’re Aurora – this could be an incredibly fast turnaround time for Intel. However on the similar time, since those are pipelined designs with an excessively robust architectural similarity, preferably Intel is not going to revel in just about as many teething issues of Rialto as they’ve Ponte. However as at all times, we’ll see what in reality occurs subsequent 12 months when Intel is nearer to handing over their subsequent accelerator.
All Roads Result in Falcon Shores
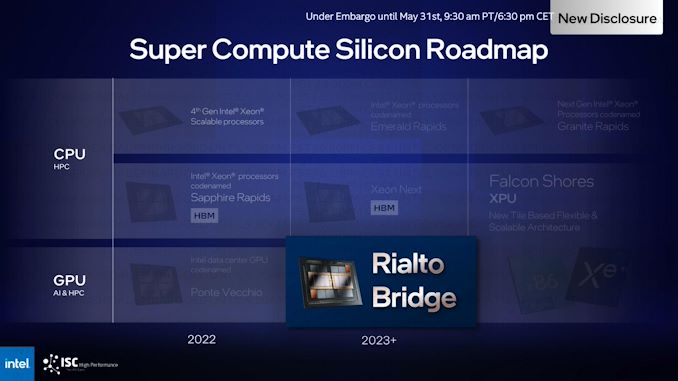
With the addition of Rialto Bridge to Intel’s HPC plans, the corporate’s present silicon roadmap looks as if the next:
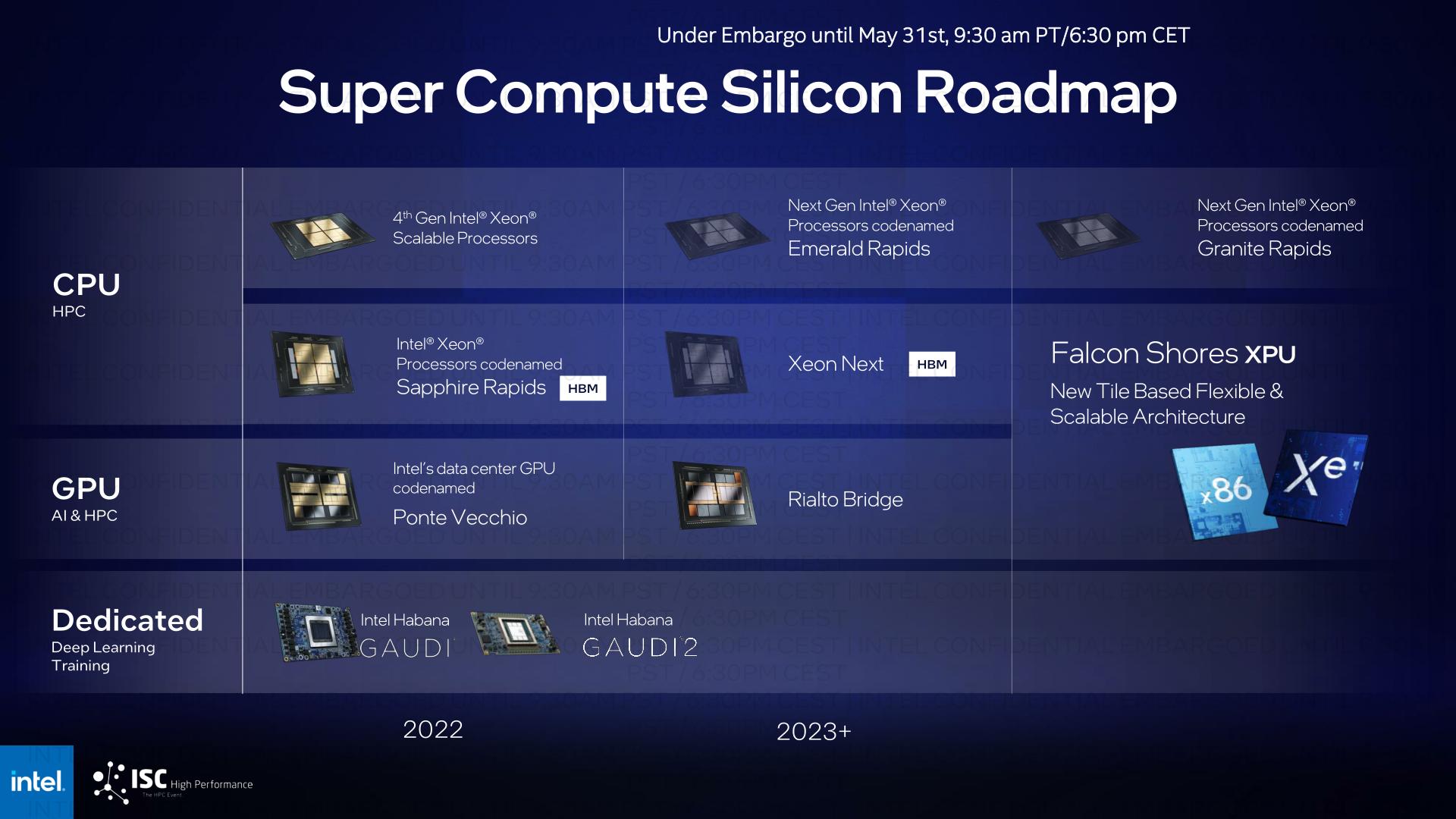
Each the HBM-equipped Xeon and HPC accelerator traces are set to merge in 2024 with Intel’s first versatile XPU, Falcon Shores. Falcon Shores was once first introduced at Intel’s iciness investor assembly previous this 12 months, and shall be Intel’s first product that takes high-performance CPU and GPU tiles to their logical conclusion by way of taking into consideration a configurable collection of every tile kind. Because of this, Falcon Shores encompasses now not most effective blended CPU/GPU designs, but additionally (slightly) natural CPU and GPU designs, which is why it’s the successor to each Intel’s HPC CPUs and HPC GPUs.

For nowadays’s match, Intel isn’t providing any more main points on Falcon Shores – so the corporate continues to be speaking about concentrated on 5x will increase in the whole lot from power potency to compute density and reminiscence bandwidth. How they intend to do so, but even so depending on their deliberate packaging and shared reminiscence applied sciences, is still noticed. However this replace does be offering a greater image of the place Falcon Shores will are compatible into Intel’s product roadmaps, by way of offering a have a look at how the present HBM-Xeon and Xe-HPC merchandise will merge into it.
In the end, Falcon Shores stays as Intel’s energy play for the HPC trade. The corporate is making a bet that having the ability to ship a tightly built-in (however nonetheless tiled and versatile) revel in with a novel API for all shall be what provides them an edge within the HPC marketplace, striking them forward of conventional GPU-based accelerators. And, if they may be able to ship on the ones plans, then 2024 is shaping as much as be an excessively fascinating 12 months within the high-performance computing trade.
Supply By means of https://www.anandtech.com/display/17421/intel-unveils-rialto-bridge-secondgen-xehpc-accelerator-to-succeed-ponte-vecchio